
Introduction
Ever wondered how Instagram applies stunning filters to your face? The software detects key points on your face and projects a mask on top. This tutorial will guide you on how to build one such software using Pytorch.
Dataset
In this tutorial, we will use the official DLib Dataset which contains 6666 images of varying dimensions. Additionally, labels_ibug_300W_train.xml (comes with the dataset) contains the coordinates of 68 landmarks for each face. The script below will download the dataset and unzip it in Colab Notebook.
if not os.path.exists('/content/ibug_300W_large_face_landmark_dataset'):
!wget http://dlib.net/files/data/ibug_300W_large_face_landmark_dataset.tar.gz
!tar -xvzf 'ibug_300W_large_face_landmark_dataset.tar.gz'
!rm -r 'ibug_300W_large_face_landmark_dataset.tar.gz'
Here is a sample image from the dataset. We can see that the face occupies a very small fraction of the entire image. If we feed the full image to the neural network, it will also process the background (irrelevant information), making it difficult for the model to learn. Therefore, we need to crop the image and feed only the face portion.

Data Preprocessing
To prevent the neural network from overfitting the training dataset, we need to randomly transform the dataset. We will apply the following operations to the training and validation dataset:
- Since the face occupies a very small portion of the entire image, crop the image and use only the face for training.
- Resize the cropped face into a (224x224) image.
- Randomly change the brightness and saturation of the resized face.
- Randomly rotate the face after the above three transformations.
- Convert the image and landmarks into torch tensors and normalize them between [-1, 1].
class Transforms():
def __init__(self):
pass
def rotate(self, image, landmarks, angle):
angle = random.uniform(-angle, +angle)
transformation_matrix = torch.tensor([
[+cos(radians(angle)), -sin(radians(angle))],
[+sin(radians(angle)), +cos(radians(angle))]
])
image = imutils.rotate(np.array(image), angle)
landmarks = landmarks - 0.5
new_landmarks = np.matmul(landmarks, transformation_matrix)
new_landmarks = new_landmarks + 0.5
return Image.fromarray(image), new_landmarks
def resize(self, image, landmarks, img_size):
image = TF.resize(image, img_size)
return image, landmarks
def color_jitter(self, image, landmarks):
color_jitter = transforms.ColorJitter(brightness=0.3,
contrast=0.3,
saturation=0.3,
hue=0.1)
image = color_jitter(image)
return image, landmarks
def crop_face(self, image, landmarks, crops):
left = int(crops['left'])
top = int(crops['top'])
width = int(crops['width'])
height = int(crops['height'])
image = TF.crop(image, top, left, height, width)
img_shape = np.array(image).shape
landmarks = torch.tensor(landmarks) - torch.tensor([[left, top]])
landmarks = landmarks / torch.tensor([img_shape[1], img_shape[0]])
return image, landmarks
def __call__(self, image, landmarks, crops):
image = Image.fromarray(image)
image, landmarks = self.crop_face(image, landmarks, crops)
image, landmarks = self.resize(image, landmarks, (224, 224))
image, landmarks = self.color_jitter(image, landmarks)
image, landmarks = self.rotate(image, landmarks, angle=10)
image = TF.to_tensor(image)
image = TF.normalize(image, [0.5], [0.5])
return image, landmarks
Dataset Class
Now that we have our transformations ready, let’s write our dataset class. The labels_ibug_300W_train.xml contains the image path, landmarks and coordinates for the bounding box (for cropping the face). We will store these values in lists to access them easily during training. In this tutorial, the neural network will be trained on grayscale images.
class FaceLandmarksDataset(Dataset):
def __init__(self, transform=None):
tree = ET.parse('ibug_300W_large_face_landmark_dataset/labels_ibug_300W_train.xml')
root = tree.getroot()
self.image_filenames = []
self.landmarks = []
self.crops = []
self.transform = transform
self.root_dir = 'ibug_300W_large_face_landmark_dataset'
for filename in root[2]:
self.image_filenames.append(os.path.join(self.root_dir, filename.attrib['file']))
self.crops.append(filename[0].attrib)
landmark = []
for num in range(68):
x_coordinate = int(filename[0][num].attrib['x'])
y_coordinate = int(filename[0][num].attrib['y'])
landmark.append([x_coordinate, y_coordinate])
self.landmarks.append(landmark)
self.landmarks = np.array(self.landmarks).astype('float32')
assert len(self.image_filenames) == len(self.landmarks)
def __len__(self):
return len(self.image_filenames)
def __getitem__(self, index):
image = cv2.imread(self.image_filenames[index], 0)
landmarks = self.landmarks[index]
if self.transform:
image, landmarks = self.transform(image, landmarks, self.crops[index])
landmarks = landmarks - 0.5
return image, landmarks
dataset = FaceLandmarksDataset(Transforms())
Note: landmarks = landmarks - 0.5 is done to zero-centre the landmarks as zero-centred outputs are easier for the neural network to learn.
The output of the dataset after preprocessing will look something like this (landmarks have been plotted on the image).
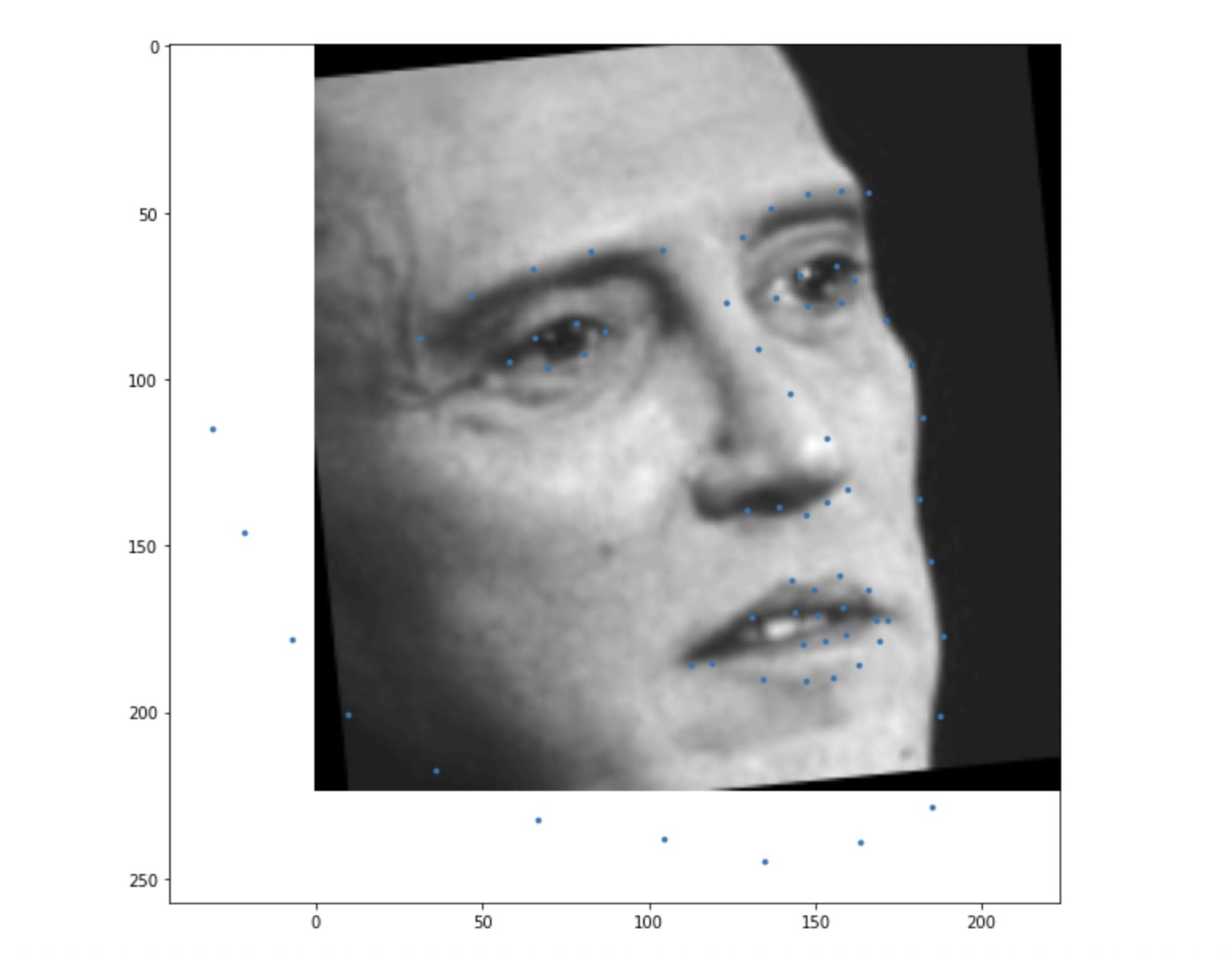
Neural Network
We will use the ResNet18 as the basic framework. We need to modify the first and last layers to suit our purpose. In the first layer, we will make the input channel count as 1 for the neural network to accept grayscale images. Similarly, in the final layer, the output channel count should equal 68 * 2 = 136 for the model to predict the (x, y) coordinates of the 68 landmarks for each face.
class Network(nn.Module):
def __init__(self,num_classes=136):
super().__init__()
self.model_name='resnet18'
self.model=models.resnet18()
self.model.conv1=nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.model.fc=nn.Linear(self.model.fc.in_features, num_classes)
def forward(self, x):
x=self.model(x)
return x
Training the Neural Network
We will use the Mean Squared Error between the predicted landmarks and the true landmarks as the loss function. Keep in mind that the learning rate should be kept low to avoid exploding gradients. The network weights will be saved whenever the validation loss reaches a new minimum value. Train for at least 20 epochs to get the best performance.
network = Network()
network.cuda()
criterion = nn.MSELoss()
optimizer = optim.Adam(network.parameters(), lr=0.0001)
loss_min = np.inf
num_epochs = 10
start_time = time.time()
for epoch in range(1,num_epochs+1):
loss_train = 0
loss_valid = 0
running_loss = 0
network.train()
for step in range(1,len(train_loader)+1):
images, landmarks = next(iter(train_loader))
images = images.cuda()
landmarks = landmarks.view(landmarks.size(0),-1).cuda()
predictions = network(images)
# clear all the gradients before calculating them
optimizer.zero_grad()
# find the loss for the current step
loss_train_step = criterion(predictions, landmarks)
# calculate the gradients
loss_train_step.backward()
# update the parameters
optimizer.step()
loss_train += loss_train_step.item()
running_loss = loss_train/step
print_overwrite(step, len(train_loader), running_loss, 'train')
network.eval()
with torch.no_grad():
for step in range(1,len(valid_loader)+1):
images, landmarks = next(iter(valid_loader))
images = images.cuda()
landmarks = landmarks.view(landmarks.size(0),-1).cuda()
predictions = network(images)
# find the loss for the current step
loss_valid_step = criterion(predictions, landmarks)
loss_valid += loss_valid_step.item()
running_loss = loss_valid/step
print_overwrite(step, len(valid_loader), running_loss, 'valid')
loss_train /= len(train_loader)
loss_valid /= len(valid_loader)
print('\n--------------------------------------------------')
print('Epoch: {} Train Loss: {:.4f} Valid Loss: {:.4f}'.format(epoch, loss_train, loss_valid))
print('--------------------------------------------------')
if loss_valid < loss_min:
loss_min = loss_valid
torch.save(network.state_dict(), '/content/face_landmarks.pth')
print("\nMinimum Validation Loss of {:.4f} at epoch {}/{}".format(loss_min, epoch, num_epochs))
print('Model Saved\n')
print('Training Complete')
print("Total Elapsed Time : {} s".format(time.time()-start_time))
Predict on Unseen Data
Use the code snippet below to predict landmarks in unseen images.
import time
import cv2
import os
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
import imutils
import torch
import torch.nn as nn
from torchvision import models
import torchvision.transforms.functional as TF
#######################################################################
image_path = 'pic.jpg'
weights_path = 'face_landmarks.pth'
frontal_face_cascade_path = 'haarcascade_frontalface_default.xml'
#######################################################################
class Network(nn.Module):
def __init__(self,num_classes=136):
super().__init__()
self.model_name='resnet18'
self.model=models.resnet18(pretrained=False)
self.model.conv1=nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.model.fc=nn.Linear(self.model.fc.in_features,num_classes)
def forward(self, x):
x=self.model(x)
return x
#######################################################################
face_cascade = cv2.CascadeClassifier(frontal_face_cascade_path)
best_network = Network()
best_network.load_state_dict(torch.load(weights_path, map_location=torch.device('cpu')))
best_network.eval()
image = cv2.imread(image_path)
grayscale_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
display_image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
height, width,_ = image.shape
faces = face_cascade.detectMultiScale(grayscale_image, 1.1, 4)
all_landmarks = []
for (x, y, w, h) in faces:
image = grayscale_image[y:y+h, x:x+w]
image = TF.resize(Image.fromarray(image), size=(224, 224))
image = TF.to_tensor(image)
image = TF.normalize(image, [0.5], [0.5])
with torch.no_grad():
landmarks = best_network(image.unsqueeze(0))
landmarks = (landmarks.view(68,2).detach().numpy() + 0.5) * np.array([[w, h]]) + np.array([[x, y]])
all_landmarks.append(landmarks)
plt.figure()
plt.imshow(display_image)
for landmarks in all_landmarks:
plt.scatter(landmarks[:,0], landmarks[:,1], c = 'c', s = 5)
plt.show()
⚠️ The above code snippet will not work in Colab Notebook as some functionality of the OpenCV is not supported in Colab yet. To run the above cell, use your local machine.
OpenCV Harr Cascade Classifier is used to detect faces in an image. Object detection using Haar Cascades is a machine learning-based approach where a cascade function is trained with a set of input data. OpenCV already contains many pre-trained classifiers for face, eyes, pedestrians, and many more. In our case, we will be using the face classifier for which you need to download the pre-trained classifier XML file and save it to your working directory.

Detected faces in the input image are then cropped, resized to (224, 224) and fed to our trained neural network to predict landmarks in them.

The predicted landmarks in the cropped faces are then overlayed on top of the original image. The result is the image shown below. Pretty impressive, right!

Similarly, landmarks detection on multiple faces:

Here, you can see that the OpenCV Harr Cascade Classifier has detected multiple faces including a false positive (a fist is predicted as a face). So, the network has plotted some landmarks on that.
That’s all folks!
If you made it till here, hats off to you! You just trained your very own neural network to detect face landmarks in any image. Try predicting face landmarks on your webcam feed!!
Colab Notebook
The complete code can be found in the interactive Colab Notebook.